")
Common Terminology (CT)
Common Terminology (CT) project is a core project of International Open Public Digital Library (IOPDL) project. The main purpose of Common Terminology (CT) project is to achieve and improve metadata interoperability between cooperating Well-Designed Digital Libraries (WDDLs) and IOPDL.
The Common Terminology (CT) project initiated and had conducted under supervision of Professor Dubin and Dean Smith during May 2012 – 2014 at Graduate School of Library and Information Science (GSLIS) in the University of Illinois at Urbana-Champaign (UIUC) in the USA.
The Common Terminology (CT) project is ongoing project at International Open Public Digital Library (IOPDL) Inc. since January of 2015, which is initiated and operated to make the public be able to access worldwide collections freely.
Currently, the Common Terminology (CT) project focuses on achieving and improving metadata interoperability between Digital Public of America, Europeana, National Library of Korea, Harvard, and MIT library with the developed Common Terminology (CT).
More details of current Common Terminology (CT) project
Quick Links to Common Terminology project website
Common Terminology (CT), www.ct.iopdl.org
- All about Common Terminology.
- CT versions:
- CT Schemas
- Crosswalks to CT:
- CT Conversion
- CT Performance by empirical evaluations
Why Common Terminology (CT) project is required?
Interoperability Problems
Interoperability issues pose a barrier to sharing and exchanging information among digital libraries and repositories. This is due to the use of diverse metadata standards, and their different degrees of generality or specificity. This causes loss of information at all metadata model levels (e.g., schema, schema definition language, record, and repository).
A Possible Solution
In response to this problem, Common Terminology (CT) based on the DCMI abstract model is suggested. The Common Terminology concept has been researching since 2011. The Common Terminology project was begun actively from May 2012, supervised by Professor Dubin and supported by Dean Smith of Graduate School of Library and Information Science (GSLIS) at the University of Illinois at Urbana-Champaign (UIUC).
The Common Terminology offers a certain way to improve interoperability allowing communities to use their choice of metadata standards but providing uniformity to search engines. CT also gives a solution to achieve interoperability among university libraries (e.g., Harvard, MIT, and UIUC), or among Well-Designed Digital Libraries (WDDLs) all around the world. CT will give an assured solution to cooperate in sharing information reducing loss of information at multiple metadata levels.
Purpose of Common Terminology (CT)
Common Terminology (CT) is to improve interoperability by allowing communities to use their own standards while providing uniformity to searching. It is to provide uniformity achieving and improving interoperability among cooperating digital libraries for IOPDL that use diverse metadata standards and have very specialized quality and quantity collections in a subject area(s). It is also to minimize loss of information and preserve accurate information. That is, it is to fulfill the technical requirement to establish IOPDL.
Definition of CT
- A Common Terminology is a set of Common Terms (including qualifiers).
- A Common Term is property (element), or class.
- A property (sub-property) can be one kind of common element (field) or attribute (subfield) in two or more metadata schemas.
- A class is “a group containing members that have attributes, [behaviors], relationships or semantics in common or a kind of category” (DCMI, 2013).
- A CTScheme is a controlled set of values that are specific to Common Terminology, including authorities, Syntax Encoding Scheme of DCMI and Vocabulary Encoding Scheme. CTScheme includes: CTTypeGenre, CTFormat, CTRelator, CTLanguage, CTDescription, CTIdentifier, and CTSubject.
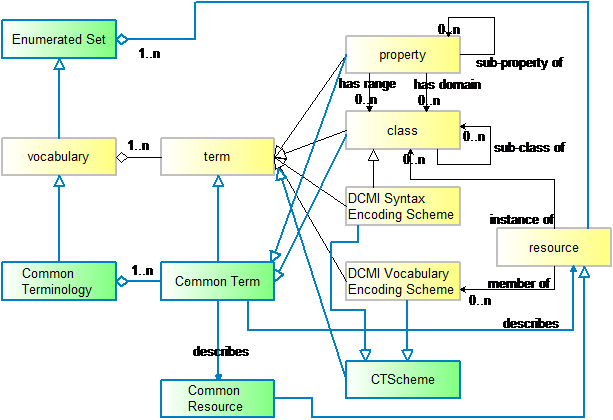
The CT Abstract Model based on DCMI abstract model (DCMI, 2013).
Roles and Benefits of CT
- First, the most important role is to embrace various metadata schemas and to provide uniformity. It allows communities to still use their best ways to describe and preserve metadata according to their needs.
- It achieves interoperability at multiple levels (schema, schema definition language, record, and repository levels). It, thus, gives a common standard way in achieving interoperability at metadata multiple levels.
- It plays a role to maintain balance between different degrees of generality or specificity of existing metadata schemas. It minimizes loss of information in transferring or mapping data between them.
- Finally, it provides a certain way that communities can share their data or databases, and work together (Jin, 2014).
CT Prototype
Taking widely used standards (MARC, MODS, DC, and QDC) as bases, a CT has been developed as a bridge across different generality and specificity levels. As a prototype, a Common Terminology is developed based on crosswalks of Library of Congress, actual metadata records, and MARC tags usage of WorldCat. The detail works for the CT project can be found in the paper, ‘A Model and Roles of a Common Terminology to Improve Metadata interoperability‘ on http://hdl.handle.net/2142/50100.
Bases
- Crosswalks of Library of Congress (e.g., MARC to MODS, MARC to DC, MODS 3.4 to MARC, MODS 3.4 to DC, DC to MODS, and DC to MARC) (LC, Conversions).
- Actual metadata records of Harvard (MARC, 12 million records), UIUC (MARCXML, 10 million), and MIT (QDC, 20 thousand) were used to investigate MARC tags usage and QDC elements usage with the specially designed Python programs.
- MARC tags usage of WorldCat and MARC tags usage in searchings are also referenced (Smith-Yoshimura, et al., 2010).
The Suggested Metadata Model Levels
CT is developed to achieve and improve interoperability at the suggested multiple metadata model levels: schema, schema definition language, record, and repository metadata model levels.
- The Metadata Schema level, with a focus on diverse schemas, lexical and semantic interoperability via crosswalks.
- The Metadata Schema definition language level, with a focus on semantic interoperability, and implementing schemas in languages such as XML or RDFs.
- The Record level, with a focus on integrating records, mapping of the elements with conversions, and lexical, semantic and syntactic interoperability.
- The Repository level, with a focus on harvesting records, mapping value strings related to specific elements, and lexical and semantic interoperability.
Developing CT
At the schema level, CT is developed to improve lexical and semantic metadata interoperability as a set of 12 Common Terms (properties) and 58 qualifiers (sub-properties) of element names of MODS for MARC, and DC & QDC with CTScheme. They are selected to minimize the gap of different degree of generality or specificity of MARC, MODS, DC and QDC. The 12 Common Terms are contributor, date, description, format, identifier, language, publisher, relation, rights, subject, title, and typeGenre. 58 qualifiers of CT 1.1 are selected to preserve much information of the 1000 MARC tags and many subfields, and elements and attributes of MODS.
At the schema definition language level, the 12 Common Terms and 58 qualifiers of the Common Terminology are represented with XML schema definition language (ct1-1.xsd) and RDF schema language (ct1-1.rdf), and SKOS concepts (ctskos1-1.rdf). These open for many communities to use CT either in XML or RDF form.
At the record level, the performance of CT in achieving and improving metadata interoperability is presented through empirical evaluations with the designed conversion. The experiments for CT are conducted with Harvard (MARC), MIT (QDC), and UIUC (MARCXML) metadata records through cooperation of three universities in the USA. The results prove that CT minimizes considerably loss of information reducing the gaps among them. CT increases significantly accuracy in mappings showing high lexical and semantic match rates.
On January of 2017, CT conversions programs are being developed to convert Metadata Application Profile(MAP) of DPLA, Library of cloud dataset of Harvard, QDC of MIT, MODS of National Library of Korea, and EDM of Europeana into the developed Common Terminology (CT). The more details about conversions are in CT Conversions website page.
At the repository level, the planned prototype is to provide a portal for DPLA, Europeana, National Library of Korea, Harvard, and MIT libraries with the built Linked Open Data and CT union catalog, connecting their several million online accessible records on the Web.
Versions
The updated CT version 1.1 Schemas
- ct1-1.xsd: CT XML Schema version 1.1 (pdf)
- ct1-1.rdf: CT RDF Schema version 1.1 (pdf)
The updated CT version 1.1 SKOS concept
The updated CT version 1.1 Crosswalks
The updated CT version 1.1 SKOS Crosswalks
The old version CT 1.1
-
CT documentation for version 1.1 is CT version 1.1 or CommonTerminology1-1(0ld).pdf.
- Common Terms are CommonTerms1-1(old).
- CT version 1.1 schema in XML is ct.xsd or ct1-1(old).xsd.
- CT version 1.1 schema in RDF` is ct.rdf or ct1-1(old).rdf.
-
CT version 1.1 in SKOS is ctskos.rdf or ctskos1-1(old).rdf.
-
The diagram of the Common Terminology 1.1 is in CT Diagram 1.1 or CT Diagram 1.1.
Prior Version CT 1.0
- CT version 1.0 schema in XML form is ct.xsd or ct1-0.xsd.
- CT version 1.0 schema in RDF` form is ct.rdf or ct1-0.rdf.
- CT documentation for version 1.0 is CT version 1.0 or CommonTerminology.pdf.
CT Performance
Through empirical mapping experiments from MARC and QDC, CT proves the high performance showing very high transfer rate, lexical and semantic match rates, and the lowest loss of information rates.
Performance of CT in achieving and improving metadata interoperability at the record level is proved through empirical evaluations with the designed conversion by Python programs. The experiments for CT are conducted with Harvard (MARC), MIT (QDC), and UIUC (MARCXML) metadata records through cooperation of three universities in the USA.
As a result of MIT (QDC) to CT conversion evaluation with 20,000 QDC records, CT shows 99.99537% transfer rate, 98.7% lexical match rate, and 100% semantic match rates. No transfer rate 0.00463% means loss of information rate is extremely low and preserve much information.
As a result of UIUC (MARCXML) to CT conversion evaluation with 400,000 MARCXML, CT shows 95.2709% transfer rate and 100% semantic match rate by SKOS concept (exactMatch rate: 55.347% and broadMatch: 44.6527%). Tag Match Rate out of Total transfer rate, 95.2709%. Non-transfer rate, loss of information rate from MARC records to CT is 4.729%. 4.729% loss of information rate is very low rate, considering that CT has only 12 common terms (less than Dublin Core) and 58 qualifiers (many fewer than MARC tags).
The results proves that CT minimizes considerably loss of information reducing the gaps between MARC and QDC and CT. CT increases significantly accuracy in mappings showing high lexical and semantic match rates. It reduces significantly the gap of different degrees of generality and specificity.